


现在的位置:主页 > 综合新闻 >
Kubernetes 新玩法:在 yaml 中编程
【作者】网站采编
【关键词】
【摘要】性能测试在日常的开发工作中是常规需求,用来摸底服务的性能。 那么如何做性能测试?要么是通过编码的方式完成,写一堆脚本,用完即弃;要么是基于平台,在平台定义的流程中进

性能测试在日常的开发工作中是常规需求,用来摸底服务的性能。
那么如何做性能测试?要么是通过编码的方式完成,写一堆脚本,用完即弃;要么是基于平台,在平台定义的流程中进行。对于后者,通常由于目标场景的复杂性,如部署特定的 workload、观测特定的性能项、网络访问问题等,往往导致性能测试平台要以高成本才能满足不断变化的开发场景的需求。
在云原生的背景下,是否可以更好解决这种问题?
先看两个 yaml 文件:
- 描述了在 K8s 中的操作流程:
1.创建测试用的 Namespace
2.启动针对 Deployment 创建效率和创建成功率的监控
3.下述动作重复 N 次:① 使用 workload 模板创建 Deployment;② 等待 Deployment 变为 Ready
4.删除测试用的 Namespace
- 描述使用的 workload 模板
:
apiVersion: /v1alpha1kind: Beidoumetadata: name: performance namespace: beidouspec: steps: - name: \"Create Namespace If Not Exits\" operations: - name: \"create namespace\" type: Task op: CreateNamespace args: - name: NS value: beidou - name: \"Monitor Deployment Creation Efficiency\" operations: - name: \"Begin To Monitor Deployment Creation Efficiency\" type: Task op: DeploymentCreationEfficiency args: - name: NS value: beidou - name: \"Repeat 1 Times\" type: Task op: RepeatNTimes args: - name: TIMES value: \"1\" - name: ACTION reference: id: deployment-operation - name: \"Delete namespace\" operations: - name: \"delete namespace\" type: Task op: DeleteNamespace args: - name: NS value: beidou - name: FORCE value: \"false\" references: - id: deployment-operation steps: - name: \"Prepare Deployment\" operations: - name: \"Prepare Deployment\" type: Task op: PrepareBatchDeployments args: - name: NS value: beidou - name: NODE_TYPE value: ebm - name: BATCH_NUM value: \"1\" - name: TEMPLATE value: \"./templates/\" - name: DEPLOYMENT_REPLICAS value: \"1\" - name: DEPLOYMENT_PREFIX value: \"ebm\" - name: \"Wait For Deployments To Be Ready\" type: Task op: WaitForBatchDeploymentsReady args: - name: NS value: beidou - name: TIMEOUT value: \"3m\" - name: CHECK_INTERVAL value: \"2s\":
apiVersion: apps/v1kind: Deploymentmetadata: labels: app: basic-1-podspec: selector: matchLabels: app: basic-1-pod template: metadata: labels: app: basic-1-pod spec: containers: - name: nginx image: /xxx/nginx:1.17.9 imagePullPolicy: Always resources: limits: cpu: 2 memory: 4Gi然后通过一个命令行工具执行 :
$ beidou server -c ~/.kube/config services/执行效果如下 (每个 Deployment 创建耗时,所有 Deployment 创建耗时的 TP95 值,每个 Deployment 是否创建成功):
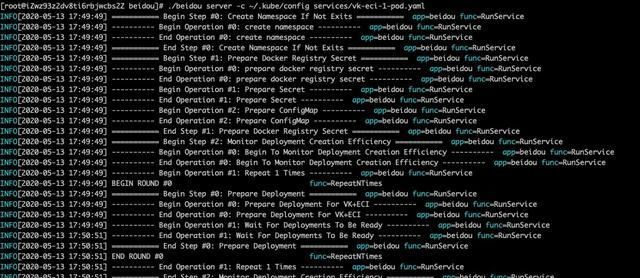
这些 metrics 是按照 Prometheus 标准输出,可以被 Prometheus server 收集走,再结合 Grafana 可以可视化展示性能测试数据。
通过在 yaml 中表达想法,编排对 K8s 资源的操作、监控,再也不用为性能测试的实现头疼了 :D
性能测试、回归测试等对于服务质量保障有很大帮助,需要做,但常规的实现方法在初期需要投入较多的时间和精力,新增变更后维护成本比较高。
通常这个过程是以代码的方式实现原子操作,如创建 Deployment、检测 Pod 配置等,然后再组合原子操作来满足需求,如 创建 Deployment -> 等待 Deployment ready -> 检测 Pod 配置等。
有没有办法在实现的过程中既可以尽量低成本实现,又可以复用已有的经验?
可以将原子操作封装为原语,如 CreateDeployment、CheckPod,再通过 yaml 的结构表达流程,那么就可以通过 yaml 而非代码的方式描述想法,又可以复用他人已经写好的 yaml 文件来解决某类场景的需求。
即在 yaml 中编程,减少重复性代码工作,通过 声明式 的方式描述逻辑,并以 yaml 文件来满足场景级别的复用。
业界有很多种类型的 声明式操作 服务,如运维领域中的 Ansible、SaltStack,Kubernetes 中的Argo Workflow、clusterloader2。它们的思想整体比较类似,将高频使用的操作封装为原语,使用者通过原语来表述操作逻辑。
通过声明式的方法,将面向 K8s 的操作抽象成 yaml 中的关键词,在 yaml 中提供串行、并行等控制逻辑,那么就可以通过 yaml 文件完整描述想要进行的工作。
文章来源:《电脑编程技巧与维护》 网址: http://www.dnbcjqywh.cn/zonghexinwen/2020/0924/505.html
电脑编程技巧与维护投稿 | 电脑编程技巧与维护编辑部| 电脑编程技巧与维护版面费 | 电脑编程技巧与维护论文发表 | 电脑编程技巧与维护最新目录
Copyright © 2018 《电脑编程技巧与维护》杂志社 版权所有
投稿电话: 投稿邮箱: